Power limiting RTX 3090 GPU to increase power efficiency
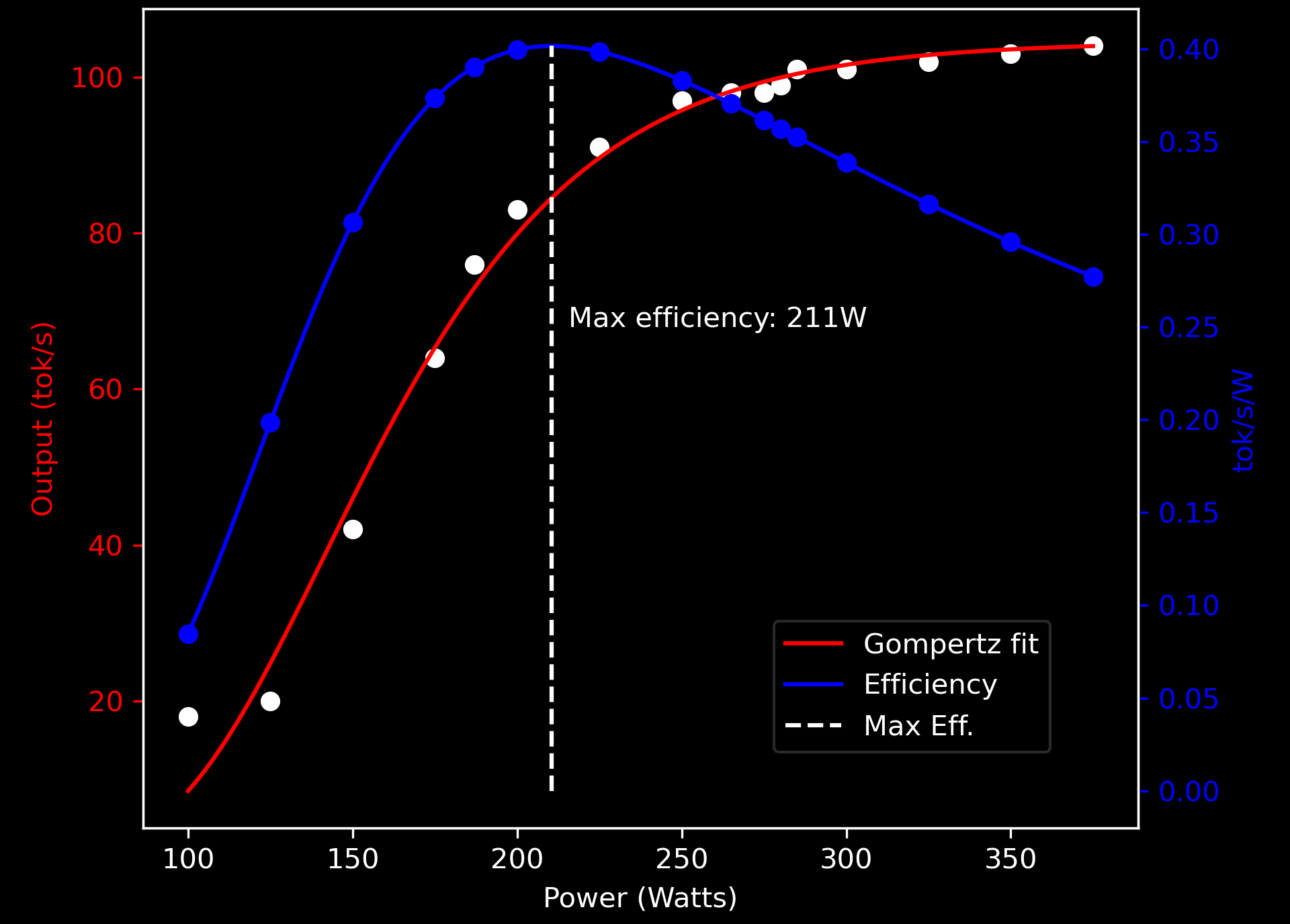
I plotted this chart and thought I'd share it in case it was useful to others. It is the tok/s output at different power limits with a RTX 3090 during single-inferencing. While maximum efficiency is achieved around 211W, this reduces output by around 20%
Running between 260W-280W gives good energy savings while maintaining nearly maximum output.
While this gives a good rule of thumb, the actual numbers will vary with the model used an particularly if batch inferencing instead of single-inferencing.
Why power limit a GPU?
Why would you voluntarily leave performance on the table when you paid a lot of money for a GPU? There are several reasons:
- The most important reason is that you don't need to leave a lot of performance on the table, the default power limits on consumer GPUs tried to squeeze the last drops of performance out of the GPU even at the expense of much higher power consumption.
By dropping performance by low single-digit percentage points, you can save double digit percentage points of power. - Reducing peak and sustained power consumption means that you will not need as powerful and expensive PSU to power the GPUs.
In some cases where otherwise multiple-PSUs are required, this can potentially eliminate additional PSUs or allow you to use cheaper and lower power rated PSUs which saves on costs and reduces complexity.
Code and Data
I had a request to share the data for the chart and I share the data and chart plotting code below:
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
# 3090 Power data
growth_data = [(100, 18), (125, 20), (150, 42), (175, 64), (187, 76), (200, 83), (225, 91), (250, 97), (265, 98), (275, 98), (280, 99), (285, 101), (300, 101), (325, 102), (350, 103), (375, 104)]
# Convert data to numpy arrays
x = np.array([t[0] for t in growth_data])
y = np.array([t[1] for t in growth_data])
yo = np.array([t[1]/t[0] for t in growth_data])
# Define the Gompertz function
def gompertz(x, a, b, c):
return a * np.exp(-b * np.exp(-c * (x)))
def gompertzx(x, a, b, c):
return a * np.exp(-b * np.exp(-c * (x))) / x
# Initial guess for parameters
p0 = [100, 0.1, 0.01]
# Fit the curve
popt, pcov = curve_fit(gompertz, x, y, p0)
#popt2, pcov2 = curve_fit(gompertzx, x, y, p0)
# Print the parameters of the fitting curve
print("Fitting parameters:")
print("a =", popt[0])
print("b =", popt[1])
print("c =", popt[2])
# Calculate the maximum value of y
x_fit = np.linspace(x.min(), x.max(), 10000)
y_fit = gompertz(x_fit, *popt)
yo_fit = gompertzx(x_fit, *popt)
max_yo = np.max(yo_fit)
max_xo = x_fit[np.argmax(yo_fit)]
# Plot the data and the fitted curve
fig, ax1 = plt.subplots()
ax1.plot(x, y, 'ko')
ax1.plot(x_fit, y_fit, 'r-', label='Gompertz fit')
ax1.set_xlabel('Power (Watts)')
ax1.set_ylabel('Output (tok/s)', color='r')
ax1.tick_params('y', colors='r')
ax2 = ax1.twinx()
ax2.plot(x_fit, yo_fit, 'b-', label='Efficiency')
ax2.set_ylabel('tok/s/W', color='b')
ax2.tick_params('y', colors='b')
ax2.plot(x, gompertzx(x,*popt), 'bo')
# Indicate the maximum value of y
ax2.plot([max_xo, max_xo], [0, max_yo], 'k--', label='Max Eff.')
ax2.annotate(f'Max efficiency: {max_xo:.0f}W', xy=(max_xo, max_yo), xytext=(max_xo+5, 0.25))
fig.tight_layout()
plt.title('RTX3090 output vs power')
fig.legend(loc=(0.6,0.2))
plt.show()Code generated with the help of LLMs!
Fitting parameters:
a = 104.54941090829679
b = 23.474054254669152
c = 0.022347470077472967Fitted coefficients
Idle power
Peak and sustained power is just one side of the equation and can help increase efficiency and reduce initial purchase costs as well as create a simpler and more compact AI server by reducing the number of PSUs required.
However there are two other things to consider:
- Controlling idle power consumption; and
- How to power multiple high performance GPUs in a single server in an efficient way.
If you'd like to see these articles, subscribe and get alerted when these follow-up articles become available.